.png)

Claude 4 Pricing Calculator







Claude 4 Cost – Compare Opus 4, Opus 4.6 / 4.5 & Sonnet 4
Your complete guide to understanding, estimating, and optimizing Claude 4 API usage.
If you’re here, I’m guessing one of three things is true:
- You’re planning to use Claude 4 (Opus 4, Opus 4.6 / 4.5, or Sonnet 4) for a project and want to avoid bill shock.
- You’re comparing Claude to GPT-4.1, GPT-4o, Gemini, or other large language models, and you want to see how the cost lines up with performance.
- You’re already using Claude and your monthly API bill keeps creeping higher — you want to cut costs without cutting results.
I’ve been in all three situations.
I’ve priced Claude for:
- Proof-of-concept AI agents for dev teams
- 24/7 customer support bots for SaaS businesses
- Academic research assistants that read hundreds of pages
- Content-generation tools for marketing teams
This page gives you all of that in one place.
Quick Claude 4 Facts — 2025 Edition
Claude 4 is no longer just two models — it’s evolving:
- Claude Opus 4.6 → Latest flagship model, best for advanced reasoning, coding, and long-running agents tasks.
- Claude Opus 4.5 → Previous flagship, still highly capable and often used as a stable baseline.
- Claude Opus 4 → Original flagship tier, premium reasoning and accuracy
- Claude Sonnet 4 → Balanced model, strong performance at a much lower cost
▶️ Pro Tip:
- Prompt caching = up to 90% cheaper if you reuse the same prompt or system message.
- Batch processing = ~50% cheaper for background jobs.
In other words, forty in-depth customer chats cost less than a latte—and you knew the budget impact before a single merge-request.
Understanding Tokens
If you’ve never worked with LLM pricing before, here’s the simplest way to think about it:
- Input tokens = what you send to Claude (your prompt, context, and instructions).
- Output tokens = what Claude sends back to you (the reply).
- Tokens are chunks of text — usually smaller than a word.
💡 Quick conversions:
- 1 word ≈ 1.3 tokens
- 1 token ≈ 4 characters (including spaces)
Example: "Hello world" = 2 words ≈ 2.6 tokens ≈ 11 characters.
How the Claude 4 Pricing Calculator Works
We created this tool to mimic how real people think, rather than how billing documents are typically written.
Step 1 — Pick your unit
You can tell the calculator your usage in:
- Tokens (best for devs tracking usage in code)
- Words (best for writers, marketers, or anyone thinking in prose)
- Characters (best for UI limits, SMS, tweets, etc.)
Step 2 — Fill in your three numbers
- Input size → How long is your prompt or the data you send?
- Output size → How long do you expect Claude’s reply to be?
- Number of calls → How many times will you send a request?
Step 3 — Get your cost instantly
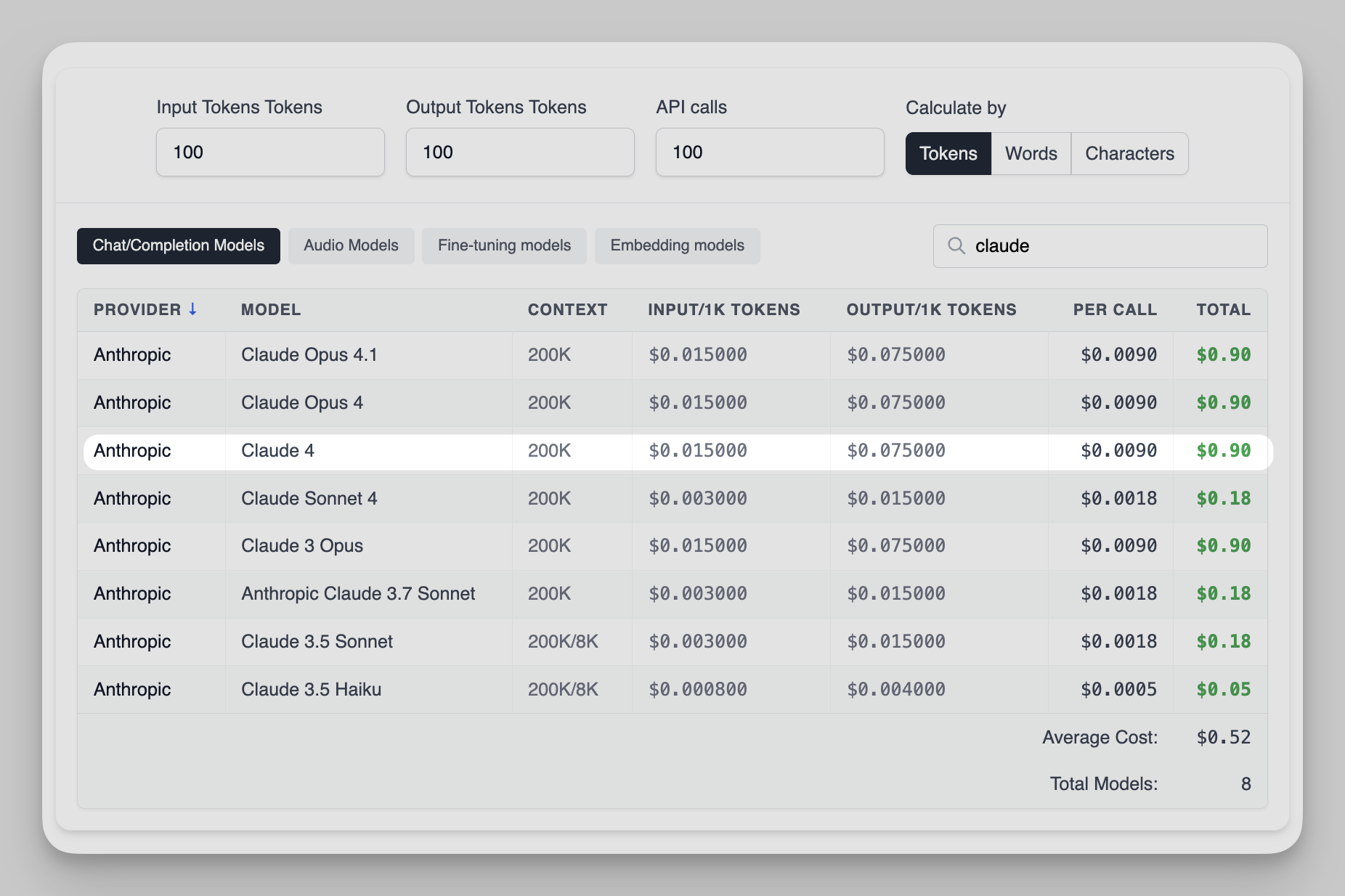
The calculator updates live and shows:
- Cost per call
- Total cost for all calls
- Side-by-side comparison for Opus 4, Sonnet 4, and other models
Official Claude 4 Pricing (2026)
Source: Anthropic launch post
Real-World Examples
Let’s walk through three real cases I’ve actually seen.
Example 1 — Customer Support Bot (Sonnet 4)
If you implement a chatbot that answers customer emails using your help docs.
- Input per chat: 600 words (customer message + chat history)
- Output per chat: 800 words (answer + follow-up)
- Calls: 15 per day × 30 days = 450 calls/month
Token math:
- Input: 600 × 1.3 = 780 tokens × 450 = 351,000 tokens (0.351M)
- Output: 800 × 1.3 = 1,040 tokens × 450 = 468,000 tokens (0.468M)
Cost:
- Input: 0.351 × $3 = $1.05
- Output: 0.468 × $15 = $7.02
- Total monthly: $8.07
With prompt caching for the system prompt → drops to about $6/month.
Example 2 — Large Code Refactor (Opus 4)
You can use Claude to help refactor multiple files in a legacy codebase.
- Input per task: 1,500 words (repo + instructions)
- Output per task: 3,000 words (code + explanation)
- Tasks: 20
Cost:
- Input: 0.039M × $15 = $0.59
- Output: 0.078M × $75 = $5.85
- Total: $6.44
Batch mode would cut that to ~$3.20 total.
Example 3 — Research Summaries (Opus 4)
If you need concise, cited reports from multiple research papers.
- Input: 4,000 words (papers + instructions)
- Output: 8,000 words (summary + citations)
- Runs: 12
Cost:
- Input: 0.0624M × $15 = $0.94
- Output: 0.1248M × $75 = $9.36
- Total: $10.30
Claude 4 vs Other LLMs
When to Choose Which Model

Go with Opus 4.6 if you…
- Need multi-hour focus on a task
- Are building AI agents that run workflows end-to-end
- Care about highest possible code accuracy
Go with Sonnet 4 if you…
- Want great performance but lower costs
- Need high-volume responses without breaking the bank
- Do lots of coding, Q&A, or summarizing where speed matters
Skip them if you…
- Just need bulk text → use Claude Haiku or GPT-4o mini
- Need instant multimodal audio/video → use GPT-4o
Five Proven Tricks to Keep Your Claude 4 Bill Low
I’ve tested this in real projects and found five proven strategies:
- Cache your system prompt — biggest savings if you reuse the same setup.
- Batch jobs — run big, non-urgent tasks in bulk at ~50% lower cost.
- Cap output length — prevent Claude from generating unnecessary text.
- Extended thinking only when needed — don’t pay for deep reasoning on simple queries.
- Use a cheaper model to pre-filter — send only the most important requests to Claude 4.
These together can cut your bill by 40–70% without hurting results.
Final Thoughts
I’ve run Opus 4 on a 7-hour autonomous coding session — it never lost track.
I’ve run Sonnet 4 on thousands of daily support chats — the cost stayed low.
If accuracy is life-or-death for your task, choose Opus 4. If you want smart, scalable AI at a lower price, choose Sonnet 4.
Who Benefits Most from Our Claude 4 Pricing Calculator?
- Developers & MLOps Engineers – budget coding agents before provisioning GPUs.
- E-commerce Growth Teams – forecast AI chatbot for customer support costs per order or per visitor session.
- Product Managers – compare Claude 4 against GPT-4.1 or o3 in one click, no spreadsheet wrangling.
- Finance & Procurement – audit every API-call assumption with a shareable permalink.
- Agencies & Consultancies – quote fixed-fee AI projects with confidence instead of padding for “token creep.”
More Free Calculators from LiveChatAI
More Free Calculators from LiveChatAI
- GPT-4.1 Pricing Calculator – Plan million-token memory projects on OpenAI’s flagship.
- OpenAI o3 Calculator – Estimate low-latency routing or classification jobs.
- Claude Sonnet 4.5 Calculator – Price mid-range chat & multilingual Q&A.
- Gemini 2.5 Pro Calculator – Budget massive-context research runs.
- DeepSeak V3 Calculator – Compare open-weights fine-tuning vs. API cost.
All benchmarks and pricing pulled from Anthropic’s “Introducing Claude 4” announcement plus publicly available model cards from OpenAI and Google.
Explore more free tools
















































Frequently asked questions

- Top-tier coding accuracy (Opus 4 scored 72.5% on SWE-bench Verified).
- Massive context capacity (200K tokens for huge inputs).
- Long-term focus for multi-hour AI agent tasks.
- Tool use & extended reasoning for complex workflows.
For high-stakes work, Claude 4 often saves money in the long run by avoiding costly mistakes.
- You’ll pay Claude’s token costs plus any costs for the other services.
- Tool calls might add extra input/output tokens because the results are fed back into Claude.
Budget for both, and test workflows end-to-end to avoid surprises.
- The longer sustained reasoning lets you automate multi-step tasks that Sonnet might need multiple calls to complete.
- You’re working in regulated industries where mistakes carry legal or compliance risks.
If you don’t see a measurable business impact from those factors, Sonnet 4 is usually the smarter default.