.png)
GPT-5 Pricing Calculator






GPT-5 Cost Calculator Guide - Plan Your API Spend
This page is your step-by-step guide to understanding GPT-5 pricing, planning a realistic budget, and squeezing maximum value from every token.
If you’ve ever been surprised by an AI bill, you’re not alone. GPT-5 is extremely capable, and with great power comes the need for clear cost controls.
Below, I’ll walk you through:
- How GPT-5 pricing works (in the most practical way possible)
- How to use the calculator (inputs → cost, step by step)
- Easy conversion rules (tokens ↔ words ↔ characters)
- When to pick GPT-5, GPT-5 mini, GPT-5 nano, or one of the newer GPT-5.4 models
- Simple tricks to cut your bill without cutting quality
Quick facts (so you can budget with confidence)

1. Models & prices (per 1M tokens):
- GPT-5. — $1.25 input, $10.00 output
- GPT-5 mini — $0.25 input, $2.00 output
- GPT-5 nano — $0.05 input, $0.40 output.
- GPT-5.4 — $2.50 input, $0.25 cached input, $15.00 output
- GPT-5.4 mini — $0.75 input, $0.075 cached input, $4.50 output
- GPT-5.4 nano — $0.20 input, $0.02 cached input, $1.25 output
2. Cached input discount (GPT-5): $0.125 Cached input can dramatically lower costs on repeated prompt segments. GPT-5 and GPT-5.4 family models both support cached input pricing, so reused system prompts, tool schemas, and fixed instructions can become much cheaper when they stay identical across requests.
3. Context & output limits: Context & output limits: GPT-5 family models support up to 400K context with 128K max output tokens, while GPT-5.4 extends context much further, up to 1,050,000 tokens with 128K max output. The calculator should account for these differences when comparing models.
4. Helpful rules of thumb for sizing text:
~1 token ≈ 4 characters of English text; 100 tokens ≈ 75 words. We use these conversions if you enter words/characters instead of tokens.
5. Extra levers developers can use: Extra levers developers can use: GPT-5 family models expose reasoning controls and verbosity-style cost levers. Use them to steer the trade-off between speed, conciseness, and depth, especially when comparing GPT-5 with GPT-5.4-class models.
Why a calculator is essential for GPT-5
GPT-5 models are built for genuinely hard work: multi-file coding, complex data reasoning, tool-rich agentic workflows, meticulous content planning, and more. And with the GPT-5.4 family now added to the lineup, the trade-off between cost, context size, and output quality matters even more when choosing the right model.
LiveChatAI’s free calculator simplifies complexity into a few easy fields, displays your estimated total in real-time, and breaks down where the money goes, so you can make smart adjustments before shipping.
How GPT-5 pricing works
1) You pay per token in and per token out
- Input tokens are everything you send: system instructions, tools schema, conversation history, and your prompt.
- Output tokens are everything the model returns: “thinking” + answer + tool call arguments (when applicable).
- Each side has its own rate. Output is significantly pricier than input across both GPT-5 and GPT-5.4 models, so long answers usually move your bill faster than long prompts.
2) Cached input is deeply discounted
If parts of your prompt repeat exactly (and meet the minimum threshold), supported GPT-5 and GPT-5.4 models apply cached input pricing to those repeated segments. This makes stable system prompts, style guides, tool specs, and reusable few-shot examples much cheaper over time.
This is perfect for stable system instructions, style guides, tool specs, or a few-shot exemplars you reuse across calls.
✴️ Good to know: OpenAI’s prompt caching runs automatically on supported models; you don’t have to enable anything special. Keep repeated portions identical to maximize the discount.
3) Context & output limits still apply
Large context and large outputs still have practical limits. GPT-5 models support about 400K context, while GPT-5.4 can go much further, up to 1.05M context on supported variants. Still, every token inside the window counts toward cost, so the calculator should flag unrealistic lengths early.
4) Words vs. characters vs. tokens
If you don’t know tokens, don’t worry. The calculator accepts words or characters and converts using OpenAI’s rules of thumb, ~4 characters per token and ~0.75 words per token, to estimate pricing. (For multilingual content the ratio varies; we’ll call that out in the results.)
How to use the GPT-5 Pricing Calculator
- Choose your measurement: tokens, words, or characters.
- Enter your input size: how large your prompt is (including any reused/system text).
- Enter your output size: how long you expect GPT-5 to reply.
- Add number of API calls: per job, per user, or across a time period.
- Review the breakdown: we’ll show input vs. output subtotals, cached vs. non-cached inputs, and the grand total, with model-by-model comparisons across GPT-5, GPT-5 mini, GPT-5 nano, GPT-5.4, GPT-5.4 mini, and GPT-5.4 nano.
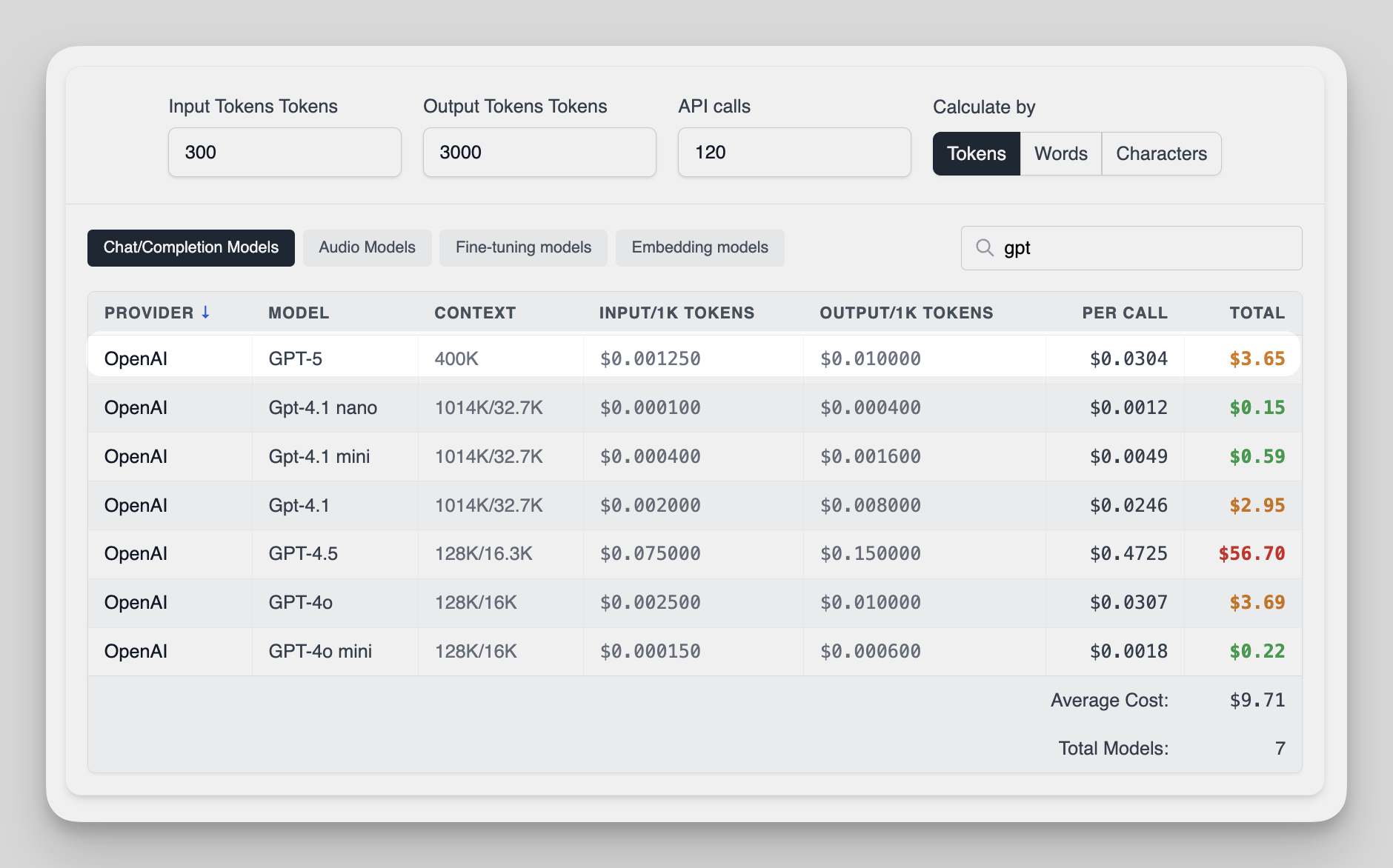
GPT-5 and GPT-5.4 vs. Other Popular LLM Models (2026 Snapshot)
If you’re wondering whether GPT-5 is worth the investment, it helps to compare not just GPT-5 itself, but also the newer GPT-5.4 family and how each model tier fits different workloads.
Today, the broader comparison set includes GPT-5, GPT-5.4, smaller cost-efficient variants like mini and nano, and competing frontier models from Anthropic, Google, and others.
In 2026, the “big four” in enterprise-grade AI are GPT-5, GPT-4.1/GPT-4o, Claude Opus 4, and Gemini 2.5 Pro, with specialized models like o1 gaining traction for niche use cases.
Here’s a quick side-by-side to help you decide where GPT-5 fits in your workflow:
Who the GPT-5 Pricing Calculator is for
- Developers & product teams shipping AI features that must stay within unit-economics.
- Support & CX leaders planning to create a chatbot or agent budgets as volume scales.
- Data & research teams running long-context analysis on large documents.
- Marketing & content teams creating structured long-form content at scale.
- Consultants & agencies producing estimates for clients before work starts.
Tips to cut GPT-5 costs (without cutting quality)
1) Be ruthless with prompt length
Keep only what the model truly needs: task, constraints, style. Put examples and schemas behind links or in a separate, cached base prompt referenced by ID (or copy-paste them identically to keep caching active). Shorter prompts reduce input tokens; shorter answers reduce output tokens (the pricier side for GPT-5).
2) Exploit cached input wherever possible
- Consolidate your system instruction and style guide into a single block you never change.
- Keep your tool schemas stable.
- Use canonical few-shot exemplars rather than creating fresh ones per request.
- Remember: the repeated segment must be identical to qualify, and caching is applied automatically where supported. Our calculator lets you model “% of prompt reused” to visualize the savings.
3) Cap the response
Set max_output_tokens to match the deliverable. If you want bullet points, you probably don’t need 3,000 tokens back. Because GPT-5 output costs $10 / 1M, trimming even a few thousand tokens in aggregate can move the needle.
4) Pick the right GPT-5 size for the job
Start with GPT-5 mini for throughput-heavy, short-form tasks; upgrade to GPT-5 when the job truly needs the extra depth. Use GPT-5 nano for ultra-cheap, latency-sensitive micro-tasks. The calculator shows all three totals so you can choose with your wallet and your quality bar in mind.
5) Tune verbosity & reasoning effort
GPT-5 exposes a verbosity parameter and a reasoning_effort control (including a minimal option). Lower verbosity usually means fewer output tokens; minimal effort may reduce thinking time and sometimes shrink output, but not every task benefits from less reasoning, so measure quality when you dial it down. Our calculator doesn’t charge for “effort” directly; it shows the impact through tokens you expect to generate.
6) Batch and summarize
For conversational use-cases, keep a running summary of the thread and include that instead of the entire history. For batch jobs, group similar prompts where feasible to reuse the same cached base instructions.
7) Prototype with realistic samples
Token counts vary by language and content type. Run a few real requests, note input/output usage, and feed those numbers into the calculator. The estimates will then match production closely.
What makes GPT-5 worth the spend?
If you’re on the fence about GPT-5 vs. a smaller model, it helps to weigh cost alongside capability:
- State-of-the-art coding & agentic tasks with stronger tool use and fewer errors, plus controls like verbosity and reasoning_effort to steer behavior.
- Big-context comprehension across long documents and multi-file code—so you can ask more ambitious questions in fewer calls.
Our calculator’s comparison view keeps the decision simple: if mini or nano meets your bar, go small; if not, you’ll at least know exactly what GPT-5 costs before you commit.
More Free Calculators & Resources from LiveChatAI
Explore additional resources to find the best AI model for your unique needs:
The bottom line
GPT-5 gives you an unprecedented blend of intelligence, control, and scale—and with a simple calculator, it’s easy to keep that power affordable. Use it to:
- Forecast costs before you commit.
- Compare models (GPT-5 vs. mini vs. nano).
- Model caching savings for reused prompts.
- Dial in output length and effort settings.
When you can see how each token affects your budget, you don’t have to guess. You can plan with confidence, choose the right model, and ship great features without the bill anxiety.
Sources and key references
- GPT-5 pricing & sizes (GPT-5, mini, nano): OpenAI — Introducing GPT-5 for developers. (openai.com)
- GPT-5 context and output token limits (family overview): OpenAI — GPT-5 landing. (openai.com)
- Cached input price for GPT-5: OpenAI API models — GPT-5. (platform.openai.com)
- Prompt caching behavior: OpenAI API docs — Prompt caching. (platform.openai.com)
- Token conversion rules of thumb: OpenAI Help — What are tokens? and OpenAI Tokenizer. (OpenAI Help Center, platform.openai.com)
Explore more free tools
















































Frequently asked questions
