
Ticket triage is the support workflow of sorting incoming tickets by urgency, impact, and topic, then routing each one to the right owner with full context. Done well, it cuts first response time, protects SLAs, and keeps high-value customers from waiting behind low-stakes tickets. These seven tips show how I run triage in 2026 with AI in the loop.
What is ticket triage?
Ticket triage is the process of sorting every inbound support ticket by urgency, business impact, and issue type, then assigning it to the right agent or queue with the right context attached. It is the gatekeeping step between "ticket arrives" and "someone actually starts solving it."
The name borrows from the emergency room. In a hospital, a triage nurse decides who gets seen first based on how serious the case is, not who walked in first. Support triage runs the same way: a paying enterprise customer reporting a checkout outage jumps the queue, while a "how do I export a CSV" question waits its turn.
I have run support ops audits across 30+ teams in the last few years, and the difference between a healthy queue and a dumpster fire almost always comes down to triage. When I see backlog spikes, missed SLAs, or agents complaining about "no one knows who owns what," the root cause is usually that incoming tickets land in one shared inbox with no priority signal and no routing rules.
If you want a deeper definition of how triage fits into the broader workflow, our guide on ticket management covers the full lifecycle from intake to resolution. Triage is the first 60 seconds of that lifecycle, and it sets the ceiling on everything that comes after.
Why ticket triage matters in 2026
Triage matters more in 2026 than it did even two years ago because ticket volume has grown faster than headcount. The teams I have audited this year are handling 30-60% more inbound volume than they did pre-2024, but most have flat or shrinking support budgets. Without triage, that math breaks: agents pick the easy tickets, the hard ones rot, and CSAT drops three to four points within a quarter.
According to Wizr.ai, the global helpdesk automation market reached about $26.8 billion in 2024, which tells you how much budget is now flowing toward this exact problem. That money is buying AI categorization, smart routing, and SLA monitoring, the three pillars of modern triage. Teams without these capabilities are competing against teams that have them, and the response-time gap is widening.
The other shift is customer expectations. Support buyers I talk to in 2026 expect a meaningful first response in under an hour for paid tiers and same-day resolution for anything tagged "urgent." Triage is what makes those numbers possible. Without it, you are guessing which ticket to pick up next, and guessing is how SLA breaches happen.
There is also a quieter cost. The average support ticket carries voice-of-customer data that compounds over time. Without categorization at intake, that signal disappears the moment the ticket closes. Teams that triage well are not just routing faster, they are building a labeled dataset they can mine later for product feedback and self-service content.
Key benefits of effective ticket triage
Triage is not just a routing chore. When it works, it changes the economics of your support team. Here are the benefits I see most often in audits:
• Faster first response on the tickets that matter: Urgent issues skip the queue and land with the right agent immediately, instead of sitting behind low-priority noise.
• Fewer SLA breaches: When priority is set at intake, your SLA timer starts on the right ticket with the right deadline. Teams I work with typically cut SLA breaches by 40-60% in the first quarter after fixing triage.
• Better agent specialization: Skill-based routing means your billing expert sees billing tickets, not random product questions. This compounds: agents get faster on their lane, and quality scores climb.
• Lower cost per ticket: Reducing back-and-forth and misroutes saves real money. Our breakdown of customer support cost shows how much time and budget gets eaten by triage friction.
• Cleaner data for product and CX teams: Categorized tickets become a labeled feedback dataset. You can finally answer "what are users complaining about this month" with a query, not a guess.
• Less burnout: Agents spend their day solving problems they are good at, not playing inbox triage tag. This shows up in retention numbers within two quarters.
The numbers backing this up are striking. According to Wizr.ai, businesses using AI for ticket triage see up to a 50% reduction in first response time. Smaller MSPs report even bigger wins on cost: a case study on NeoAgent shows Excellent Networks saving over $40,000 per year by eliminating the dedicated triage position entirely once AI took over the sorting.

Ticket triage numbers in 2026.
7 ticket triage tips for faster, better support
These seven tips are ordered the way I implement them when I take over a struggling support queue. Tip one fixes the worst leak (a fragmented inbox), and each tip after that builds on the last. You can ship the first three in a week. Tips four through seven take a quarter to do well, but the payoff compounds.
1. Centralize the inbox
Centralizing the inbox means every inbound support touch, email, chat, social DM, in-app message, phone call, lands in one shared system with one ticket schema. No more "the billing question came in via Slack, but the bug report came in via email, and nobody saw the Twitter mention." One pipe, one queue.
This is tip one because nothing else works without it. I have walked into teams running five separate inboxes and watched the same customer issue get answered three times by three different agents with three different answers. That is not a triage problem yet, that is a plumbing problem. Fix the plumbing first.
How I roll this out:
1. Audit every existing intake channel for the last 30 days. Count tickets by source. You will find at least one channel nobody knew was a support channel (usually a generic info@ alias or a forgotten Twitter handle).
2. Pick a single helpdesk platform as the system of record. Every channel either forwards into it or syncs into it via API.
3. Set up channel forwarders within 5 business days. Email aliases, social monitoring, in-app widgets, all routed to the same queue.
4. Lock down the side doors. Tell agents and account managers: do not answer support questions in DMs. If a customer pings you directly, create a ticket on their behalf so it gets tracked.
Effort: low to medium. Most teams I work with finish this in 5-10 days. The immediate impact is visibility: leadership sees real ticket volume for the first time, and that number is usually 30-50% higher than the number they thought they had.
2. Define crystal-clear priority levels
A priority level is only useful if everyone on the team applies it the same way. "High priority" means nothing if one agent uses it for "the customer is angry" and another uses it for "their site is down." You need written, example-driven definitions that fit on one page.
I use a four-tier model in almost every engagement: P0 outage, P1 critical, P2 standard, P3 low. The exact names matter less than the criteria behind them. The criteria are usually a combination of business impact (how many users affected, what revenue is at risk), urgency (is the customer blocked right now), and contract tier (paid enterprise versus free trial).
How to define priorities that hold up:
1. Write the definitions with two real example tickets per level. Pull them from your own backlog so the team recognizes the patterns.
2. Tie each priority to an SLA target right in the definition. P0 = first response within 15 minutes. P2 = first response within 8 business hours. No SLA, no priority.
3. Run a calibration session with the whole team. Show 20 sample tickets, have everyone rate the priority, then discuss the disagreements. You want over 90% agreement before you ship the model.
4. Print the one-pager and pin it. Or pin it in your team Slack. Agents need to glance at the criteria, not navigate to a Notion doc.
3. Automate categorization with AI
Manual categorization is where good triage goes to die. The average team spends hours each day just sorting, tagging, and routing incoming requests before anyone actually starts solving problems. That time is pure overhead, and AI can take most of it.
AI categorization works by reading the ticket body, matching it against historical tickets, and assigning a category, intent, and suggested priority before a human ever opens it. Modern models do this well enough that I trust them to set the first-pass tag on roughly 85-90% of tickets, with humans reviewing the edge cases.
How I set this up:
1. Export 1,000-2,000 historical tickets with their final category labels. This is your training set. The model learns your taxonomy from your own data.
2. Start with a narrow tag schema: 8-12 top-level categories, not 40. Common buckets are billing, account access, bug, feature request, how-to, refund, integration, abuse. You can subdivide later.
3. Run AI categorization in shadow mode for two weeks, where the AI tags tickets but does not route them yet. Compare AI tags against human tags daily. Once agreement hits 85%, flip routing live.
4. Always keep a human override. If an agent retags a ticket, that signal feeds back into the model. Never make AI tags read-only.
The case for this is direct. AI triage models learn from historical ticket data and adapt to new patterns without manual rule updates, which means your categorization gets better the more you use it instead of decaying like a static rules engine. For broader context on what AI changes in support workflows, our guide on AI in customer service walks through the full benefit set.
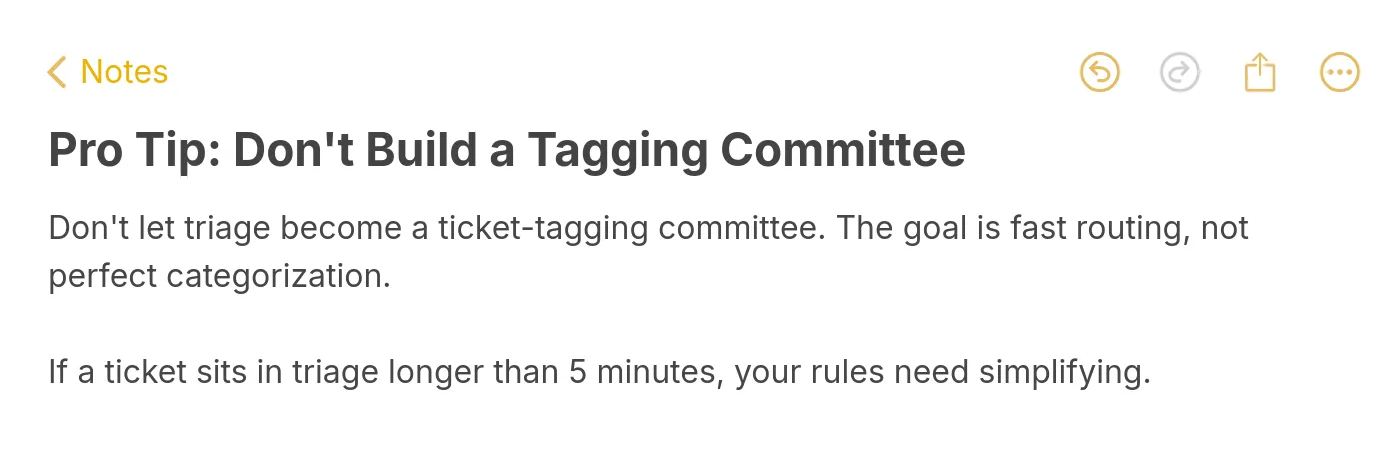
Pro tip on triage speed vs. perfect tagging.
4. Set SLA timers per priority
An SLA without a timer is a wish. Once you have priority levels defined (tip 2), every ticket needs a clock attached at the moment of intake, and that clock needs to be visible to the agent and to leadership. No clock, no accountability, no SLA.
The mistake I see most often is teams writing SLA targets into a contract or service page but not actually instrumenting them. The agent has no idea their P1 ticket is 45 minutes from breach. The manager finds out three days later in a weekly report. That is too late.
How to instrument SLA timers:
1. Wire SLA targets directly into the ticket view. Every agent should see "time remaining: 1h 23m" on every open ticket, color-coded by how close to breach.
2. Build a breach-imminent alert. When a ticket hits 25% of its SLA window remaining, ping the assigned agent and a backup. At 10%, page the team lead.
3. Pause the timer on customer-blocked tickets. If you are waiting on info from the customer, the clock should pause and resume when they reply. Otherwise your SLA numbers will lie about agent performance.
4. Report breaches weekly, not monthly. A monthly view hides patterns. Weekly forces the team to spot recurring breach types fast and fix the upstream cause.
One tactical note: do not start with aggressive SLAs. Look at your current p90 response time, set the SLA there, and tighten it by 10-15% per quarter as the team gets faster. Setting a 15-minute P0 SLA when your current p90 is 4 hours just demoralizes everyone.
5. Route tickets by skill, not seniority
Skill-based routing means a ticket about Stripe webhooks goes to whoever on the team is best at Stripe webhooks, regardless of whether they are a junior or a lead. Seniority-based routing, where leads handle "hard" tickets and juniors handle "easy" ones, sounds reasonable and is almost always wrong.
Here is why seniority routing fails. "Hard" and "easy" are not stable categories. A billing ticket might be trivial for the agent who lived in the Stripe dashboard last month and a nightmare for the lead who has not touched billing in a year. When you route by seniority, you are matching tickets to titles, not to actual ability.
How to ship skill-based routing:
1. Build a skills matrix. Rows are agents, columns are categories or product areas. Each cell is a 1-3 score: 1 = can handle, 2 = strong, 3 = expert. Update it quarterly.
2. Set routing rules off the matrix. When a ticket gets a category tag, the routing engine picks the highest-scored available agent. Tie-breaker is current workload.
3. Cap concurrent assignments per agent at 5-8 active tickets. Beyond that, quality drops fast. Excess routes to the next-best skilled agent.
4. Build the bench. Every category should have at least three agents at score 2 or higher. If one person is the only Stripe expert, they become a bottleneck on vacation. Cross-train deliberately.
I have watched skill-based routing cut average resolution time by 30-45% on teams that previously round-robined everything. The reason is simple: less context-switching, fewer escalations, fewer "let me check with someone" replies that double the ticket lifecycle.
6. Track first-touch and time-to-route metrics
Most teams track first response time and resolution time. They miss the two metrics that actually tell you whether triage is working: first-touch time (intake to first human action, including tagging) and time-to-route (intake to assignment). These are the leading indicators. First response and resolution are lagging.
If your time-to-route is 45 minutes, no amount of agent skill will save your first response SLA. The ticket is already 45 minutes old before the assigned agent even sees it. Triage is the bottleneck, and you cannot fix what you do not measure.
What to instrument:
1. Time-to-tag: intake timestamp to first category tag applied. Target under 2 minutes with AI categorization.
2. Time-to-route: intake timestamp to first agent assignment. Target under 5 minutes for P0/P1, under 30 minutes for P2/P3.
3. Re-route rate: percentage of tickets that get reassigned at least once after initial routing. Healthy is under 10%. Above 15% means your categorization or skills matrix is wrong.
4. Triage abandonment: tickets that sit in "untagged" or "unassigned" for more than 30 minutes. This number should be zero. If it is not, your AI categorization is failing on edge cases and there is no fallback.
Pull these into a dashboard the team lead checks every morning. Not every week, every morning. The point of leading indicators is that they tell you about problems before they show up in the customer-facing numbers.
7. Run a weekly triage retro
The weekly triage retro is a 30-minute team meeting that exists for one purpose: catch the patterns your dashboards do not show. Numbers tell you what changed. The retro tells you why, and what to do about it.
I run this with three artifacts. First, a list of every SLA breach from the past week with the root cause filled in (was it triage misroute, agent overload, customer blocker, or product bug). Second, the top 10 tickets by re-route count, because those are pointing at a category definition problem. Third, a "weird tickets" pile, the ones the AI categorizer flagged with low confidence so a human had to step in.
How to run a triage retro that ships changes:
1. Time-box at 30 minutes, hard. Anything that needs more than 30 minutes becomes a follow-up doc. The retro is for surfacing, not solving.
2. Rotate the facilitator. Different agents notice different patterns. The lead noticing everything every week is a sign you are not getting full team input.
3. Each retro must produce 1-3 written changes. A new category. A revised priority criterion. A skills matrix update. If you finish a retro with no changes, you wasted the meeting.
4. Track changes against outcomes. Did adding a "subscription cancellation" category cut re-routes on billing tickets by 20%? Write that down. Otherwise you will keep proposing the same fixes.
The compounding effect is the point. After 12 retros, your categorization is sharper, your routing rules are tighter, and your team has built a shared mental model of what triage means. That shared model is what separates teams that scale support smoothly from teams that hire their way out of every backlog spike.
How to set up AI triage in LiveChatAI
If you want to put tip 3 (AI categorization) into practice today, here is how the setup looks in LiveChatAI. The whole flow takes about 20 minutes for a first triage AI Action and uses the AI Actions feature, which lets the chatbot collect inputs and route them based on rules you define.
Step 1: Log in to LiveChatAI
Sign in to your LiveChatAI dashboard. If you do not have an account yet, create one and connect your data sources (knowledge base articles, past tickets, FAQ pages) so the AI has context to categorize from.
Sign in to LiveChatAI.
Step 2: Open the AI Actions tab
From the chatbot dashboard, navigate to the AI Actions tab. This is where you build the workflows that the chatbot can execute on behalf of users, including ticket triage. Click Create AI Action to start a new workflow.
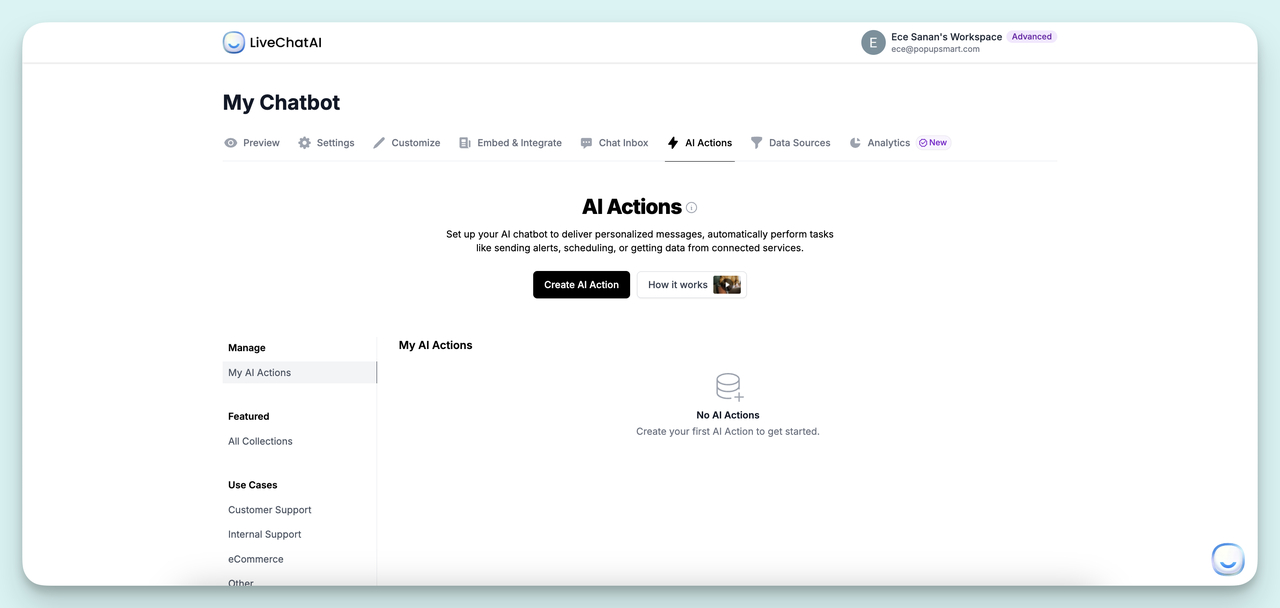
Open the AI Actions tab.
Step 3: Define the trigger condition
The trigger condition tells the chatbot when to fire the triage flow. Write it in plain language. Examples that work well: "When a user describes a product issue or bug," or "When a visitor asks for help with their account or billing." Be specific. Vague triggers like "when a user needs help" will fire on every conversation and create noise.
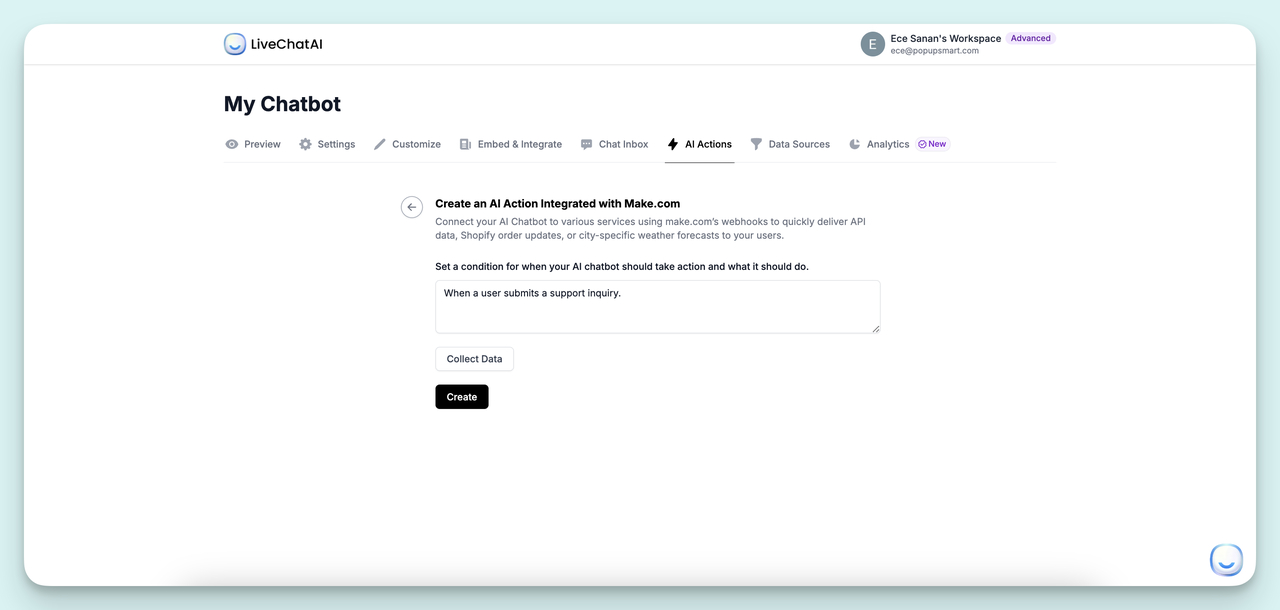
Configure the trigger condition.
Step 4: Add input fields with clear descriptions
Use the Collect Data step to define the inputs the chatbot should gather before routing. Typical fields are issue category (billing, technical, account, feature request), priority signal (is the customer blocked right now), and contact info. The descriptions you write here are what the chatbot uses to ask the user, so they need to be conversational and specific. "Describe the issue you are facing in a few words" is better than "issue."
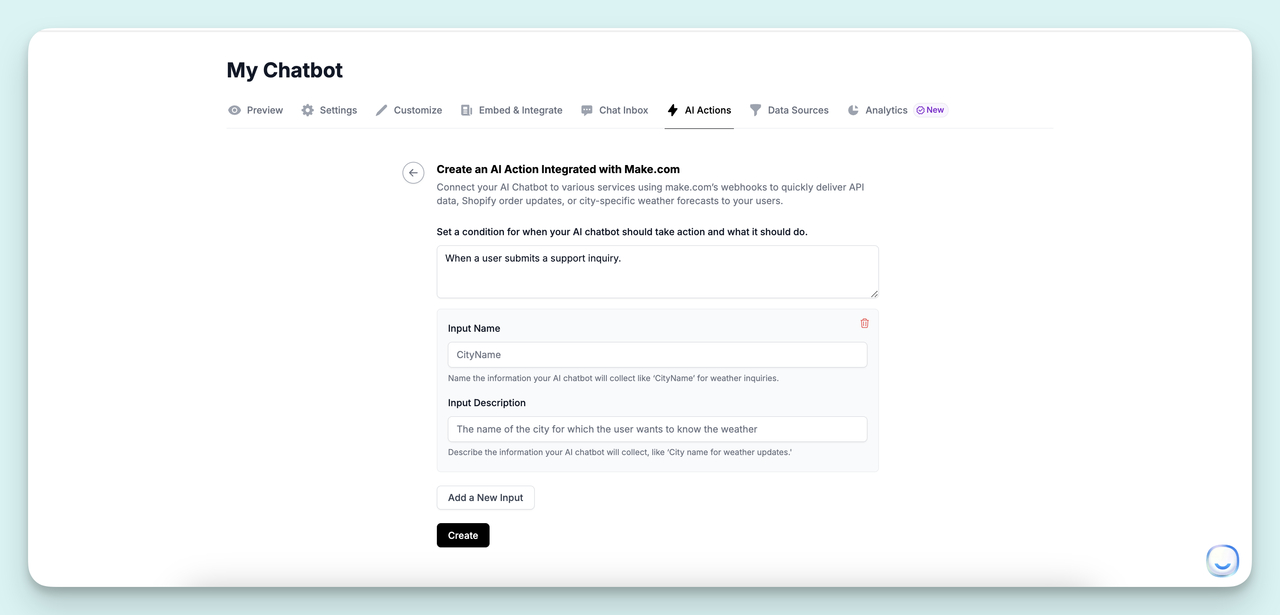
Describe each input field clearly.
Once the inputs are saved, connect the AI Action to your downstream tools. Zapier, Make.com, webhooks, and direct API calls all work, so you can drop a triaged ticket straight into your helpdesk, Slack channel, or whatever system owns your queue. Test with a few sample conversations before going live, and watch the categorization quality for the first week. For more on how chatbots fit into the broader support stack, see our breakdown of chatbot use cases across industries.
Common ticket triage mistakes to avoid
Most triage failures are not exotic. They are the same four or five mistakes repeating across every team I audit. Knowing them upfront saves you a quarter of trial and error.
• Treating triage as a perfect-categorization problem: Triage is a routing problem, not a taxonomy problem. If you spend more time arguing about whether a ticket is "billing" or "subscription billing" than you save by tagging it, your taxonomy is too granular. Aim for fast and 85% accurate, not slow and 100% accurate.
• Letting low-priority tickets rot: A common reaction to overload is to ignore P3 tickets. Three weeks later, those P3 customers churn quietly without ever escalating. Every priority level needs an SLA, even if the P3 SLA is 5 business days. Silent churn is more expensive than slow response.
• Routing by who is online instead of who is right: When the team is stretched thin, it is tempting to route everything to whoever has free hands. This breaks skill-based routing in week one. Better to let a P3 wait 30 extra minutes for the right agent than to misroute it and add two reassignments.
• Not feeding the AI categorizer back: AI categorization decays if you do not feed agent corrections back into the model. I have walked into teams whose AI accuracy dropped from 88% to 71% over a year because the feedback loop was never wired. Set this up on day one.
• Skipping the retro: Tip 7 exists because most teams will not run it. They will set up triage, watch the metrics improve, and stop iterating. Six months later the categories no longer match the product, the skills matrix is stale, and the queue is sluggish again. The retro is what keeps triage healthy.
Ship a faster triage workflow this quarter
If you only do three things from this guide, do these. Centralize the inbox in week one so you can actually see your queue. Define priority levels and tie them to SLA timers in week two so the queue self-organizes. Stand up AI categorization in weeks three and four so your team stops spending hours a day on sorting work a model can do in seconds.
Everything else (skill-based routing, leading-indicator metrics, weekly retros) is the layer that makes triage compound over time. You do not need it in month one. You will need it by month three, and waiting until month six to add it is what causes the second wave of triage problems most teams hit.
If you want to skip the manual setup, LiveChatAI's AI Actions handle categorization and routing out of the box once you connect your knowledge base and helpdesk. Start with a free account, point it at your top 1,000 historical tickets, and watch first-response time drop in the first two weeks. That is the fastest triage win available to support teams in 2026.
Frequently asked questions
Who should triage tickets?
In a small team of under 10 agents, everyone shares triage as the first step before they pick up a ticket. In a team of 10-30, you typically have a rotating triage shift where one or two agents own intake for a 4-hour block. Beyond 30 agents, you usually want a dedicated triage specialist plus an AI categorizer handling the obvious cases. The split I see most often in 2026 is AI handles 80-90% of categorization automatically, and a single triage specialist handles edge cases and escalations.
Can you triage a ticket over the phone?
Yes, and for urgent issues phone triage is often the fastest path. The agent assesses the issue in real time, sets priority on the call, logs the ticket with notes, and either resolves it inline or routes it to the right specialist. The catch is that phone triage requires well-trained agents who know the priority criteria cold. Without that training, phone calls become a side door that bypasses your routing rules entirely. Make sure your phone agents are following the same priority and category schema as your email and chat triage.
What does ticket triage include?
Ticket triage covers four steps that happen between intake and assignment: incident logging (capturing the customer's issue, context, and contact info), categorization (tagging the ticket by issue type and product area), prioritization (setting urgency based on impact and SLA tier), and assignment (routing the ticket to the right agent or queue with the right context attached). In modern setups, the first three steps are usually automated by AI, and a human only steps in when the model has low confidence or when the ticket needs special handling.
How is AI triage different from rule-based routing?
Rule-based routing uses static if-then logic. "If the email contains 'refund', send it to billing." It works for predictable patterns but breaks the moment language varies. AI triage reads the full ticket context, compares it to historical tickets, and assigns category, priority, and routing based on patterns it has learned. The practical difference is maintenance: rule-based engines need constant updating as your product and customer language change, while AI models adapt as new tickets arrive. For teams over 5,000 tickets per month, the maintenance savings alone usually pay for AI triage in the first quarter.
How do you measure if triage is working?
The four metrics I watch are time-to-tag (intake to first category applied), time-to-route (intake to assignment), re-route rate (tickets reassigned after initial routing), and SLA breach rate by priority. If all four are trending in the right direction, triage is healthy. If time-to-route is fine but re-route rate is climbing, your categorization is wrong. If breach rate spikes only on P1 tickets, your skills matrix has a gap. Each metric points at a different fix.
Explore more blog posts:
What is Ticket Management? Key Points & Practices



