
A self-learning AI chatbot is a conversational system that uses machine learning and natural language processing to improve its answers over time, without manual rewrites for every new question. It learns from real user chats, feedback signals, and outcome data, then retrains itself so the next answer is better than the last.
What is a self-learning AI chatbot?
A self-learning AI chatbot is a chatbot that gets smarter with use. Instead of running on a static script, it watches what people actually ask, how they react, and which answers solve the problem. Then it updates its own model so the next conversation goes better.
The simplest way to picture it: a rule-based bot is a flowchart. A self-learning bot is a junior support agent who reads every ticket, takes notes after every escalation, and slowly learns the product. After three months, the rule-based bot still answers exactly the same way it did on day one. The self-learning bot answers differently, because it has seen 40,000 chats since then.
Three things make a chatbot "self-learning" rather than just "AI-powered":
• It ingests new data on a schedule: fresh help docs, new product releases, recent ticket transcripts, updated pricing pages. Old context gets replaced, not stacked.
• It captures feedback signals: thumbs-up and thumbs-down clicks, "did this answer your question?" follow-ups, agent escalations, and resolution outcomes flow back into the training set.
• It retrains or re-embeds regularly: either the underlying model gets fine-tuned on the new data, or the retrieval index gets rebuilt with the new content, so future answers reflect what the bot just learned.
Without all three, you've got a smart bot, not a self-learning one. I've shipped self-learning chatbots for SaaS teams since 2022, and the bots that actually improve over time always have a closed loop. The ones that plateau are the ones where someone forgot to wire feedback into retraining. If you want a refresher on the broader category before going deeper, here's what is an AI chatbot in plain language.
How a self-learning AI chatbot actually learns
Self-learning happens in a loop, not a single pass. Five stages, each feeding the next.
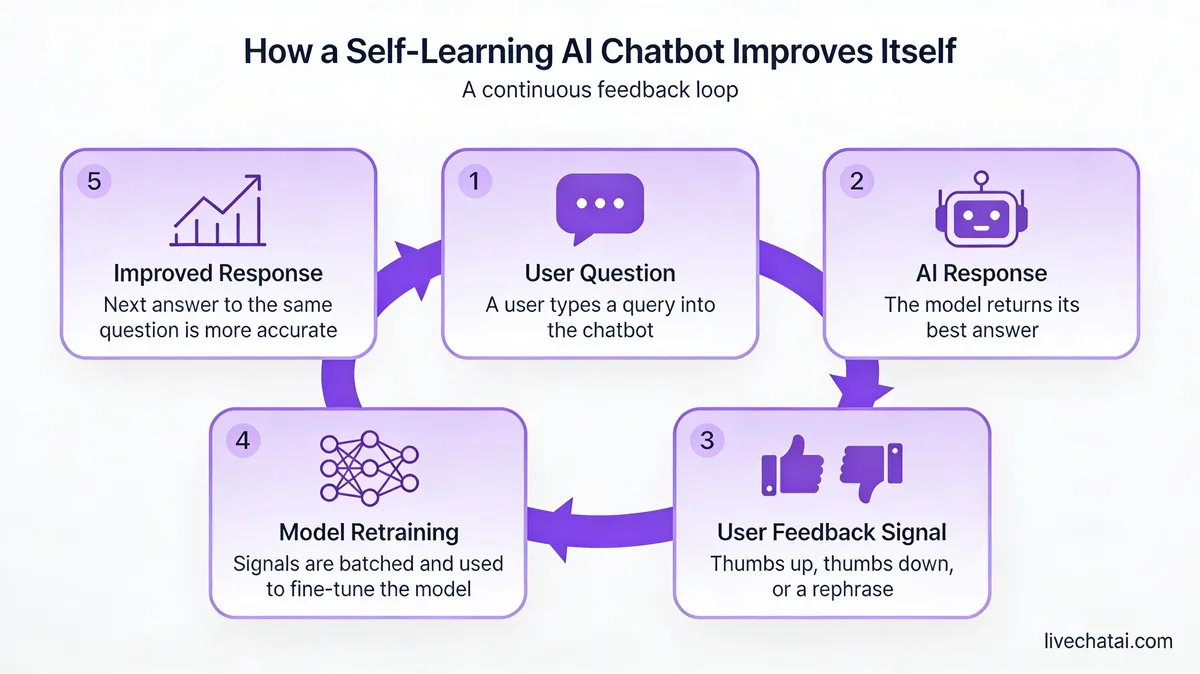
1. Training data ingestion. The bot starts with a corpus: help center articles, product documentation, past chat transcripts, FAQ pages, knowledge base entries, sometimes Slack threads or Notion pages. For most LiveChatAI customers I work with, the initial corpus is 200 to 800 documents. Anything smaller and the bot guesses too much. Anything bigger on day one and you can't tell what's noise.
2. Embedding and intent matching. Each document chunk gets converted into a vector — a numeric fingerprint of its meaning. When a user asks a question, that question is also embedded, and the bot retrieves the closest-matching chunks. NLP then maps the user's phrasing to an intent ("refund request," "cancel subscription," "integration help") so the response template is appropriate. This is the same retrieval-augmented generation (RAG) pattern most modern bots use.
3. Response generation. An LLM stitches the retrieved chunks into a natural reply, citing sources where it can. Good bots refuse to answer when retrieval confidence is low, instead of inventing something. That refusal behavior is one of the strongest signals of a healthy self-learning setup.
4. Feedback capture. Every reply gets a thumbs-up or thumbs-down option. Some bots also ask, "did this solve your issue?" and watch whether the user keeps typing or closes the chat. Agent escalations count too — if a human took over within 30 seconds of the bot's reply, that's a vote against that answer. In our customer audits, bots that capture under three feedback signals per session don't generate enough data to improve.
5. Retraining and re-indexing. Negative-feedback turns become training examples for the next fine-tune or get flagged for human review. New help docs and edited articles trigger a re-embedding job, so the retrieval index reflects the latest truth. Cadence depends on volume: weekly for high-traffic bots, monthly for lower volume. Skip this step and your bot freezes in time.
If you want a deeper walkthrough of the corpus side specifically, the playbook for how to train AI on your data covers the ingestion piece in more detail.
Self-learning vs rule-based vs LLM-only chatbots
Three architectures get called "AI chatbots" in marketing copy. They behave very differently in production.
Rule-based chatbots follow if-then logic. The user types "refund," the bot routes to the refund flow. Anything outside the script returns a fallback message ("I didn't understand, please rephrase"). They're cheap to build, predictable, and brittle. After watching 100+ chatbot rollouts, I'd say rule-based bots cap out at about 30-40% containment for general support — they handle the FAQ, then dump everything else on a human.
LLM-only chatbots wrap a large language model around a system prompt and let it answer freely. They sound great in demos. In production, they hallucinate confidently, contradict your help docs, and have no memory of which answers worked. There's no learning loop — every conversation is an island. They're fine for top-of-funnel marketing chat where being wrong is low-stakes. They're a liability for billing, accounts, or healthcare.
Self-learning chatbots sit in the middle. They use an LLM for natural language, but ground it in your verified content via retrieval, then close the loop with feedback and retraining. The LLM provides fluency. Your data provides truth. Feedback provides improvement. This is the architecture that gets bots from 40% containment on day one to 70-85% containment by month six, which is roughly what we see across LiveChatAI deployments.
The shorthand: rule-based is a script, LLM-only is a confident guesser, self-learning is a system that learns from being wrong. If you're still mapping out the difference between conversational systems more broadly, AI virtual assistants covers the wider category.
Key benefits of self-learning AI chatbots
The real payoff is operational, not magical. Here's what teams actually see when the loop is wired correctly, with numbers from sources that publish their methodology.

• Higher containment without rewriting flows: a self-learning bot improves answers from real chats, so you don't have to manually script every edge case. One published case study from Overthink Group reports 83% of chat communications handled entirely by the bot at Charter — about 166,000 requests per month off the human queue.
• Faster human agents when the bot does hand off: agents jump into a conversation with full context — what the user asked, what the bot tried, what the user thumbed-down. Research from Harvard Business School found AI helped human agents respond about 20% faster, with a bigger lift for less experienced agents.
• Lower cost per resolved ticket: a chat the bot resolves costs cents. A chat that requires a human costs dollars. As containment moves from 40% to 70%, the per-ticket blended cost drops sharply — usually the line item that justifies the project to finance.
• 24/7 coverage without a night shift: the bot doesn't sleep, so 2am questions from your APAC users get answered in real time instead of waiting eight hours for a US-morning response.
• Better data on what's actually broken: the bot's negative-feedback log is the cleanest list you'll ever get of where your help docs are wrong, missing, or outdated. Treat it as a product backlog, not a chatbot problem.
• Compounding accuracy: rule-based bots stop improving the day you stop editing them. Self-learning bots get better passively, as long as feedback flows in and retraining runs on schedule.
• Market validation: per Ringly, the generative AI chatbot segment is now worth $12.98 billion and growing 31.11% CAGR — faster than the overall chatbot market. Roughly 987 million people use AI chatbots globally, according to Orbilon Tech. The category isn't speculative anymore.
Real-world self-learning AI chatbot use cases
Four scenarios where self-learning chatbots earn their keep, drawn from teams I've worked with directly or watched closely.
E-commerce returns and order status
Returns are the #1 ticket type for most online stores, and they're 80% the same five questions: where's my order, how do I return, when will I be refunded, can I exchange instead, do you ship to my country. A self-learning bot ingests order data via API, the returns policy page, and shipping carrier statuses. It answers in real time and learns the edge cases (international shipping delays, holiday cutoffs, sale-item exceptions) from feedback over the first 60 days. Containment of 70%+ on returns is realistic. Black Friday is where it earns its keep — a small e-commerce team I worked with handled 4x normal volume without a single new hire.
SaaS knowledge base support
SaaS products generate the same setup, billing, and integration questions on repeat. A self-learning bot trained on the help center, API docs, and changelog can resolve onboarding friction at 2am, when your London users are waking up and your support team is asleep. The feedback loop is especially valuable here — when a new feature ships, negative thumbs on questions about it tell you exactly which docs need updating, often before the support team notices. I've seen new-user activation lift 8-12% just from faster answers in the first 30 minutes after sign-up.
Healthcare appointment FAQs
Patient-facing chatbots in clinics handle a narrow but high-volume slice: appointment booking, location and hours, insurance accepted, what to bring, prescription refill process. Self-learning matters here because medical terminology varies wildly — patients describe symptoms in dozens of ways. A bot that learns "stomach hurt" maps to "abdominal pain" maps to "GI consult" gets meaningfully better month over month. The hard rule for healthcare: the bot stays in scope (admin questions only), refuses to give medical advice, and escalates anything clinical to a human within seconds. Self-learning improves the routing, never the diagnosis.
Financial services account help
Banks and fintechs use self-learning bots for balance checks, transaction lookups, card replacement, statement requests, and fraud-flag explanations. The compliance bar is high — the bot must never invent product terms or rates — so RAG-grounded answers with strict source citation are the norm. The self-learning piece kicks in on phrasing: customers ask "why is my card declined" 47 different ways, and the bot learns which retrieval chunks resolve each phrasing best. Chatbot QA matters more here than anywhere else, because a wrong answer about a fee schedule is a regulatory problem.
How to train and deploy a self-learning chatbot in 5 steps
The order matters. Skip step 4 and the bot won't actually learn — it'll just be an LLM with a logo.
1. Collect and clean your data. Pull every help center article, product doc, FAQ, and the last 90 days of resolved chat transcripts. Strip out PII, internal notes, and outdated content. Most teams underestimate the cleaning step — half the bad chatbot answers I diagnose trace back to a stale help article that contradicted a newer one. Aim for 200-800 high-quality documents on day one. More volume means more contradictions to resolve.
2. Set up your intents and fallback behavior. Define the top 20-30 intents the bot needs to handle (cancel, refund, integration help, pricing, etc.). For each intent, decide what success looks like and what triggers an escalation. Define the fallback explicitly: when retrieval confidence is below threshold, the bot should say "I'm not sure — let me get a human" rather than guessing. This refusal behavior is the single biggest predictor of trust over time.
3. Choose your model and retrieval setup. For most B2B SaaS use cases, a hosted RAG platform beats rolling your own — you get the embedding pipeline, vector store, and feedback hooks out of the box. If you go custom, plan for an embedding model (OpenAI, Cohere, or open-source like sentence-transformers), a vector database (Pinecone, Weaviate, pgvector), and an LLM endpoint. Latency target: under 2 seconds end-to-end. Anything slower and users abandon mid-question.
4. Wire up the feedback loop. This is the step everyone skips and regrets. Every reply needs thumbs-up and thumbs-down. Every escalation needs a reason code. Every resolution needs a "did this help?" follow-up. Pipe all three signals into a database you can query weekly. Build a dashboard showing top failed intents, top retrieval misses, and top thumbs-down chunks. Without this dashboard, no one will know whether the bot is improving or drifting.
5. Monitor, retrain, and ship updates weekly. Pick a cadence — weekly is the sweet spot for most teams — and run the same checklist: review the top 20 thumbs-down replies, fix the underlying docs or add training examples, re-embed the corpus, regression-test the top 50 intents, ship. The bots that improve fastest treat this like a product release, not a chore. The bots that plateau are the ones where retraining is "when we get around to it." If you want a structured QA approach, the chatbot QA guide goes deeper.
Common self-learning AI chatbot pitfalls and how to avoid them
Four ways self-learning chatbots break, ranked by how often I see them.
Bad training data. Garbage in, garbage out. The most common offender: outdated help articles that nobody archived. The bot pulls a 2023 pricing page, the user gets a wrong number, the support team gets an angry email. Fix it by treating your help center as the bot's source of truth — do a quarterly content audit, archive anything older than 18 months unless re-verified, and tag content with "last reviewed" dates the bot can use to weight recency.
No feedback wiring. If thumbs-up/thumbs-down isn't on every reply and the data doesn't flow into a dashboard you actually look at, your bot isn't self-learning. It's just an LLM with a logo. Fix it by making feedback collection a launch requirement, not a phase-two improvement. Day one or never.
Drift. The bot was great in month one, mediocre in month four, embarrassing in month seven. Usually one of two causes: nobody is retraining (so the index is stale) or product changes outpaced doc updates (so the source of truth is wrong). Fix it with a weekly retrain cadence and a hard rule that no feature ships without a docs update merged to the bot's corpus.
Hallucination. The bot invents a feature, a price, or an integration that doesn't exist. This almost always traces back to weak retrieval grounding — the bot is filling gaps in your docs with the LLM's general knowledge. Fix it by tightening the confidence threshold, requiring source citation in answers, and explicitly training the bot to say "I don't know" when retrieval confidence is low. A bot that refuses 5% of questions is more trustworthy than one that confidently makes things up.
Get started with a self-learning chatbot this quarter
The teams who succeed with self-learning chatbots don't start with a 12-month roadmap. They ship something narrow in three weeks and iterate.
Pick one ticket type that's high-volume and low-risk — order status, password reset, FAQ-style product questions. Pull the relevant help docs and the last 90 days of resolved transcripts for that ticket type. Stand up a hosted bot, scope it to that one intent plus a "talk to a human" fallback, and ship feedback collection on day one. Run it for two weeks. Review the thumbs-down log, fix the docs, retrain, ship again.
If the bot resolves 50%+ of that one ticket type after a month, you have a green light to expand. If it doesn't, you've learned exactly which docs are wrong before you scaled the problem. Either outcome is a win.
If you want to compare deployment options before committing, the rundown of AI chatbot alternatives walks through the trade-offs between platforms.
Frequently asked questions
Which AI is best for self-learning chatbots?
For most teams, a hosted RAG platform built on GPT-4 class or Claude class models beats building from scratch — you get embeddings, retrieval, and feedback hooks out of the box. If you have a strong ML team and unique data, fine-tuning an open-source model (Llama, Mistral) on your transcripts can outperform on niche domains. The "best" depends on your latency budget, compliance requirements, and whether your data can leave your infrastructure.
How can I train my own AI chatbot?
Pick a hosted platform that lets you point at a website or upload documents, then iterate from there. The flow looks like: upload your help docs and FAQs, define a few intents and a fallback message, embed a chat widget on your site, ship feedback collection from day one, and review the thumbs-down log weekly. Most teams have a working v1 in under a week. Scaling it to 70%+ containment takes 3-6 months of iteration.
How does machine learning enable self-learning in chatbots?
ML provides three things a rule-based bot can't: pattern recognition (mapping diverse user phrasings to the same intent), generalization (handling questions the bot has never seen by interpolating from similar ones), and adaptation (updating its model from new data without manual rewrites). Without ML, every new question type requires a new rule. With ML, the bot infers the rule from examples.
Can self-learning AI chatbots integrate with SaaS platforms?
Yes — most modern chatbot platforms expose REST APIs and webhooks, plus pre-built connectors for the common stack: Slack, Salesforce, HubSpot, Zendesk-class helpdesks, Shopify, Stripe. The integration pattern is usually: bot reads from your data sources via API, posts conversation logs to your analytics warehouse, and triggers downstream workflows (create ticket, refund order, schedule callback) via webhook. Plan for OAuth and rate limits before you plan for the bot.
For further reading, you might be interested in the following:
15 Positive Reviews Response Examples to Use
How to Integrate WhatsApp for Your Website
How Do AI Chatbots Qualify Leads? (with Strategies and Examples)



