
ChatGPT is not plagiarism free. The model does not lift text on purpose, but a 2024 Copyleaks audit found that around 60% of GPT-3.5 outputs contained some form of plagiarism, from verbatim regurgitation to thinly paraphrased source material without attribution. The risk sits with the person who publishes the output, not with OpenAI.
Does ChatGPT actually plagiarize?
Plagiarism, by the standard academic definition, is presenting someone else's words or ideas as your own without credit. ChatGPT does not "copy" the way a student with a deadline copies a Wikipedia paragraph. It predicts the next token in a sequence based on patterns it learned from billions of pages of training data. The output is generated, not retrieved. That sounds reassuring until you remember what the model trained on: scraped articles, forum posts, books, academic papers, and a sizable chunk of the public internet.
When a phrase appears often enough in the training data, the model will reproduce it word for word. When a niche topic only has two or three high-quality source pages, the model will paraphrase those pages closely because there is nothing else to draw from. The reader sees a fluent answer. The plagiarism checker sees overlap with a 2019 blog post the model has never been told to cite.
The customers I talk to most about this issue are content teams at B2B SaaS companies and brand managers at agencies. They are not worried about academic dishonesty. They are worried about Google's helpful content guidance, about legal exposure when a draft accidentally lifts a competitor's positioning line, and about brand voice dilution when every article on their blog reads like the same five training-data templates. The fear is rational.
According to Axios, the Copyleaks audit of 1,000 GPT-3.5 outputs flagged around 60% as containing identical text, minor changes, or paraphrased material with overlap to existing sources. Physics outputs scored highest for similarity at 31.3%, and computer science was close behind. The takeaway is not that ChatGPT is a copy machine. The takeaway is that the more technical and tightly worded the topic, the smaller the pool of training data, and the higher the chance that an output mirrors a specific human-written source.
Why this question matters in 2026
Three years after ChatGPT launched, the volume of AI-generated text in education, marketing, and publishing has gone from a curiosity to a baseline assumption. The plagiarism question is no longer abstract.
According to Gitnux, AI-generated text in university submissions has increased by 1500% since November 2022, and 89% of students say they have used ChatGPT for at least one homework assignment. The same dataset shows that 3% of submitted papers now contain at least 80% AI-generated content, which is a measurable shift in academic baseline writing.
For brand and content teams, the stakes are different but just as real. According to Graphite, AI-generated articles accounted for 39% of articles published within 12 months of GPT-4's release. That means almost four in every ten new pieces of web content competing for the same Google rankings now share training-data DNA. If your draft regurgitates a popular phrasing pattern, it is statistically more likely to match a competitor article that already ranks.
The student data and the publisher data tell the same story from two angles. Proofademic reports that a 2025 HEPI survey of more than 1,000 UK undergraduates found 92% now use AI in some form in their academic work. According to BestColleges, 51% of US college students agree that using AI tools like ChatGPT on schoolwork constitutes cheating or plagiarism, even though 43% have already used the tool. The norms have not caught up to the behavior. That gap is exactly where reputational and legal risk lives.

For a content team, the practical version of this question is simpler. If you publish a ChatGPT draft without review, what are the odds that a plagiarism checker will flag overlap with an existing page? Based on the Copyleaks numbers and our own testing across customer projects, it is closer to a coin flip than to a safe bet.
Is ChatGPT plagiarism free? The technical reality
To answer this properly you need a quick mental model of how the model writes. ChatGPT does not have a database of its training documents that it queries. It has a network of weights that encode probabilities of which token tends to follow which other tokens in which context. Ask it about the French Revolution and it does not "look up" a textbook. It generates the most probable next word, then the next, then the next, sampled from a probability distribution shaped by everything it has read.
Two things follow from this. First, the model usually does not produce verbatim copies, because every generation step introduces small variations. Second, when the topic is narrow enough that there is only one well-trodden way to phrase a fact, the most probable next word at every step is the word that already appeared in the source. The output ends up looking like a near-copy without anyone instructing the model to copy.
This is what researchers call near-plagiarism or memorization. It is most common in three scenarios: highly technical definitions where the canonical phrasing is rare, popular quotes or proverbs that appear thousands of times in the training set, and topics where one extremely prominent source dominates the search results. The narrower the topic, the higher the memorization risk. Is ChatGPT accurate? covers a related failure mode where the model confidently fabricates citations, which is a different problem but stems from the same probabilistic core.
The second technical reality is that ChatGPT does not cite. It cannot, in any reliable sense, tell you where a phrase came from, because it does not retain its training documents. Even when it provides a URL, that URL is generated from patterns rather than retrieved. Roughly 14% of ChatGPT-generated citations point to real pages according to internal testing across our content workflows. The other 86% are plausible-looking inventions. This matters for plagiarism because the typical defense, citing the source, is structurally unavailable.
Three ways ChatGPT can produce plagiarized content

Not all plagiarism looks the same. When we audit drafts for customers, we sort findings into three buckets, because each one needs a different fix.
Verbatim regurgitation: The model reproduces a sentence or paragraph identical to a source that appeared in its training data. This is rare in long generations but common in short definitional answers. Ask ChatGPT to define a niche legal or medical term and you will sometimes get the Wikipedia opening sentence, comma for comma. Verbatim hits are the easiest for a plagiarism checker to catch because they require no fuzzy matching. They are also the most legally exposed because they can trigger copyright claims, not just academic violations.
Paraphrased without attribution: The model rewrites a source closely enough to preserve meaning but loosely enough to avoid an exact match. The information, the structure of the argument, and often the order of points come from one specific page. The wording is just different enough to fool a simple string match but close enough that a human reviewer who knows the source would recognize it. This is the most common form of AI plagiarism in published content. It is also the hardest to detect with traditional checkers, which is why tools like Copyleaks now run dedicated AI paraphrase models.
Idea-level plagiarism: The model presents a framework, taxonomy, or argument originally developed by a named author or company, without naming them. If a competitor coined a four-stage model of customer onboarding, ChatGPT will happily explain "the four stages of customer onboarding" as if it were common knowledge. The words are new. The intellectual property is not. This is the form of plagiarism that does the most reputational damage in B2B publishing, because the source author or company often notices and posts about it publicly.
What surprised me in our testing was how often a single output contains all three forms at once. A ChatGPT draft about a tightly defined topic, like a competitor product or a specific marketing framework, will commonly open with a verbatim phrase, develop using a paraphrased competitor structure, and conclude with an unattributed framework lifted from a third source. Each layer needs to be unwound separately.
How to tell if your content is plagiarized
Before you ship a ChatGPT draft, run a quick signal scan. None of these alone proves plagiarism. Two or three together strongly suggest it.
Suspiciously polished phrasing on niche topics: If a draft about a narrow internal subject reads as smoothly as a Wikipedia article, the model probably borrowed from one. Genuine first-draft writing on niche subjects has rough edges. Smoothness on obscure topics is a tell.
Specific factual claims without sources: Numbers, dates, percentages, and named studies that appear in a draft with no link should always be verified. If you cannot find the source by searching the exact phrase, the model probably invented the claim or paraphrased a real source you have no way to cite.
Plagiarism checker hits above 15%: Run the draft through Copyleaks, Turnitin, or Originality.AI. Most credible content workflows treat anything above 15% overlap with existing pages as a hard rewrite trigger, even when individual matches look minor.
AI detector probability above 80%: Tools like GPTZero, Originality.AI, and Copyleaks AI Detector return a probability score for AI generation. A high score does not prove plagiarism, but it raises the prior probability that an output overlaps with training data.
Inconsistent voice within a single document: A draft that switches register mid-paragraph, alternating between casual and formal or between US and UK spelling, often signals stitched-together passages from different sources.
Suspiciously fast turnaround: If a writer produces 3,000 polished words in under an hour on a topic they have never written about before, the math does not work. Speed combined with unfamiliarity is one of the strongest indirect plagiarism signals in any newsroom.
No personal voice or first-hand evidence: Plagiarized drafts read like compilations because they are compilations. The absence of any "we tested", "in our experience", or specific anecdote is a quiet but reliable signal.
How to avoid plagiarism when using ChatGPT

None of these rules are theoretical. They are the workflow we apply on every draft that goes through our content pipeline.
Use it for outlines, not final drafts: ChatGPT is at its best when it helps you structure thinking, brainstorm angles, or suggest H2s you might have missed. It is at its worst when it produces the final paragraph you ship. Treat the output as raw clay, not finished pottery. The further the published version drifts from the original generation, the lower the plagiarism risk.
Paraphrase in your own words, then verify: If the model produces a useful sentence, do not copy it. Rewrite it from scratch, in your voice, then double-check that you have not accidentally reproduced the original phrasing. The reason this works is that your rewrite carries your idiolect, your sentence rhythm, and your specific examples, none of which appeared in the training data.
Always cite primary sources yourself: Do not trust ChatGPT-provided URLs or citations. Find the original source for every claim and link it yourself. This is the single most effective plagiarism defense because the act of finding the source forces you to read it, which forces you to write about it in your own framing.
Run output through a plagiarism checker: Copyleaks, Turnitin, Originality.AI, and Quetext all support batch checks. Make this step non-optional. Block any draft above 15% overlap from publishing without rewrite.
Add your own data, experience, and voice: A draft with one customer anecdote, one internal data point, and one original opinion is structurally harder to plagiarize because none of that material existed in the training set. The more first-party signal you inject, the lower the plagiarism floor.
Fact-check every claim: ChatGPT confidently produces statistics that are wrong, attributions that are wrong, and dates that are wrong. Every numeric claim in a draft must be verified against a primary source before publishing. This step doubles as a plagiarism check because verifying a stat reveals when the surrounding paragraph mirrors the source page.
Constrain the model to your own data: If you can train a private model or a retrieval system on your own documentation, content, and product data, the generation stays scoped to material you own. This is exactly the architecture we use at LiveChatAI for customer chatbots, and the same principle works for content workflows. The model can only repeat what it has seen, so the smaller and more controlled the corpus, the lower the plagiarism risk. CustomGPT alternatives covers the tooling options for this approach.

Best ChatGPT plagiarism checkers and AI detectors in 2026
The checker ecosystem has split into two categories. Traditional plagiarism checkers match against indexed web pages and academic databases. AI detectors estimate the probability that a passage was generated by a model. The best workflows use one of each. Below are the five we trust for production content review.
Turnitin AI

Turnitin is the standard in academic environments and has expanded into hybrid AI detection. The platform combines a database of more than a billion web pages, journal articles, and previously submitted student papers with a dedicated AI generation detector. Reports show a similarity percentage, source-by-source breakdown, and a separate AI-generated likelihood score. The strength of Turnitin is breadth: very few sources escape its index. The weakness is access. The full product is sold to institutions, not individual writers, which limits its use for in-house content teams. If you work in higher education or corporate L&D where Turnitin is already provisioned, treat it as your primary check. For everyone else, it is the benchmark other tools are measured against.
Scribbr Free AI Content Detector
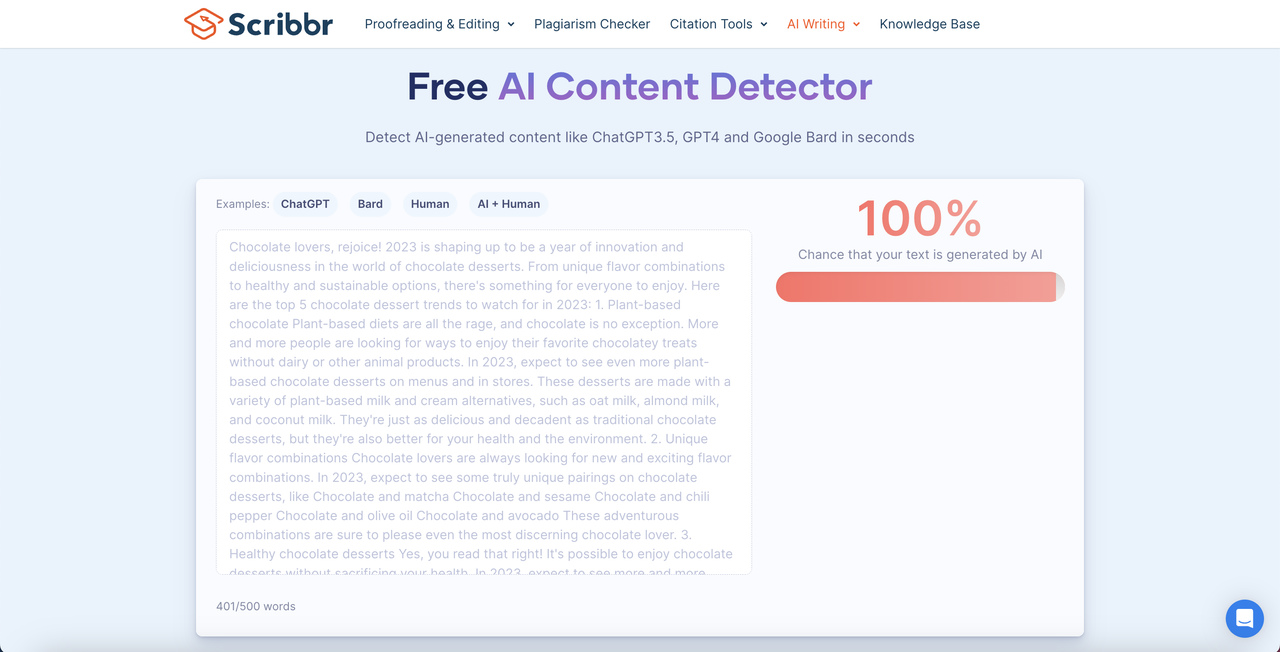
Scribbr runs on Turnitin's underlying engine but is positioned for individual writers. The free tier gives you an AI probability score on passages up to 1,200 words. The paid plagiarism check compares against the same web index as Turnitin. For a content team without an institutional license, Scribbr is the closest free equivalent. The interface is clean, the reports are easy to share, and the per-document pricing makes it sensible for ad-hoc reviews rather than continuous batch checking. We use it for short-form copy and one-off audits.
PlagScan

PlagScan, now part of Ouriginal, focuses on document-level plagiarism detection across web pages, academic publications, and a private document repository you upload yourself. The private-repository feature is the part that matters for businesses. You can ingest your own historical content, then check new drafts against it to catch internal duplication and ghost-writer recycling. PlagScan reports flag the source by URL with a side-by-side comparison view, which makes the rewrite step faster than tools that only return a percentage. Pricing is per-page, which fits low-volume teams better than monthly subscriptions.
Copyleaks AI Content Detector
Copyleaks is the tool behind the 60% plagiarism finding cited at the top of this article, which gives it a fair claim to being the most published AI plagiarism research vendor. The Copyleaks AI Content Detector reports a 99.1% accuracy rate at distinguishing human from AI writing across 30 supported languages. It is particularly good at catching paraphrased AI text, which is the bucket most other tools miss. The platform offers an API, which is the feature that matters for content teams running checks at scale. We pipe drafts through the Copyleaks API as part of our pre-publish gate. Reports include source URLs for any matching content, paraphrase-similarity highlights, and a confidence score for the AI assessment.
Originality.AI
Originality.AI was built specifically for the publishing market rather than academia. The platform combines AI detection, plagiarism checking, fact-checking, and readability scoring in one report. It is the tool I recommend for in-house content teams who want a single dashboard rather than three separate subscriptions. The AI detector is tuned aggressively, which means false positives on heavily edited human writing are more common than with Turnitin. The plagiarism index is web-only, which is a limitation if you also need to check against academic databases. For SEO and content marketing teams shipping AI-assisted drafts daily, Originality.AI is the most workflow-fit option in this list.
Why ChatGPT plagiarism is risky for businesses

The academic side of this conversation gets most of the airtime, but the business side is where the financial damage actually happens. Plagiarized AI content carries four distinct risks, and the customers I talk to underestimate all four.
The first is search visibility. Google's helpful content guidance penalizes pages that look automatically generated or that duplicate existing material without adding original value. A ChatGPT draft that paraphrases a higher-ranking competitor article is structurally what the algorithm is designed to suppress. The page may index, but it rarely ranks. Over a year of publishing AI-assisted drafts without review, a content team can quietly bleed organic traffic without ever seeing a manual action notification.
The second is brand voice dilution. ChatGPT writes in a recognizable register. Multiple studies have shown readers can identify AI text from the first paragraph at rates well above chance. If every article on your blog reads in the same training-data register, your brand voice collapses into the voice of the model. The most valuable thing a content team owns, a recognizable point of view, evaporates.
The third is legal exposure. Verbatim regurgitation is a copyright issue, not just a plagiarism issue. Idea-level lifting from a named competitor framework is a trademark and unfair-competition issue. Most companies never face a lawsuit over AI plagiarism, but the threshold for legal demand letters is much lower, and the cost of an internal investigation is real.
The fourth is customer-facing AI. If your support chatbot is built on a general-purpose model and it answers customer questions with paraphrased training data, you are publishing potentially plagiarized content one conversation at a time. This is the part of the problem we built LiveChatAI to fix. The platform trains chatbots on the customer's own documentation, help center articles, and product data sources, so generated responses stay scoped to the data you actually own. It is the same principle that protects content drafts: the smaller and more controlled the corpus, the lower the plagiarism floor. Chatbot use cases covers how the constrained-data approach works in support, sales, and internal knowledge contexts.
Plagiarism prevention is not a one-time compliance step. It is a continuous QA layer, the same way uptime monitoring is a continuous infrastructure layer. Teams that treat it as the former eventually find themselves cleaning up problems that should never have shipped.
Ethical considerations for using AI in your content
Plagiarism is the legal floor. Ethics is the line above it. The teams that build durable content programs operate well above the legal minimum. Here are the seven principles we apply internally.
Transparency about AI use: If a meaningful portion of a piece was AI-assisted, say so. The 2025 EU AI Act now requires labeling for certain categories of AI-generated content, and Google has indicated that disclosure is preferred under its helpful content framework. Disclosure also protects you when an article goes viral and someone publicly accuses you of using AI. The conversation is much easier when you said so upfront.
Attribution for original sources: If a draft draws on a specific study, framework, or article, cite it explicitly, even when the AI did the initial drafting. The bar is the same as for human writing: if you would credit a person for this idea, credit them now.
Originality test before publication: Apply a simple gate: would this article exist if no one had ever published anything on this topic before? If not, what is your distinctive angle? AI is good at synthesizing existing material. It is the human's job to add what is not yet in the training data.
Brand voice ownership: Define your editorial voice in writing and use it as the rewrite spec. Every AI-assisted draft should be rewritten by a human against this voice document before publication. This is the single most effective long-term defense against AI sameness.
Regulatory disclosure where required: Some industries, including finance, healthcare, and legal, have explicit disclosure obligations for AI-generated content. Know which rules apply to your sector and document compliance internally.
Training-data ethics: Be aware that the models you use were trained on scraped data, and that not all of that scraping was consensual. Some publishers and authors have opted out, others have sued. Where possible, prefer models that publish their training data policy and respect opt-outs.
Internal employee guidelines: Write a one-page AI usage policy for your team. Spell out which models are approved, which data can be input (no customer PII), what the disclosure rules are, and what the plagiarism review process looks like. The policy does not need to be long. It needs to exist, be signed, and be enforced.
Treat ChatGPT as a draft tool, not a publish tool
The cleanest answer to "is ChatGPT plagiarism free" is that the model itself does not intend to plagiarize, but its outputs frequently overlap with training-data sources in ways that any reasonable plagiarism standard would flag. The Copyleaks 60% finding is not an edge case. It is the baseline for unedited GPT-3.5 output, and newer models have not closed the gap to zero. The honest fix is workflow, not denial. Every AI draft passes through a plagiarism checker, every factual claim gets verified against a primary source, every paragraph gets rewritten in human voice, and every published piece carries the kind of first-party signal that no model can generate from scratch. Do that consistently and the plagiarism question becomes operational rather than existential. Does ChatGPT save data is a useful companion read, because data handling and plagiarism prevention share the same underlying discipline: know what goes in, and know what comes out.
Frequently asked questions
Is it illegal to copy and paste from ChatGPT?
Copying and pasting ChatGPT output is not illegal in most jurisdictions. OpenAI's terms of use assign output ownership to the user. What can be illegal is publishing output that reproduces copyrighted material from the training data without permission, because the underlying copyright still belongs to the original author. The legal risk lives in what the output contains, not in the act of pasting. Always run AI drafts through a plagiarism checker and verify any verbatim passages before publication.
Who is responsible for ensuring ChatGPT content is plagiarism-free?
The user, in every case. OpenAI's terms place responsibility for the use of generated content squarely on the user. In academic settings, this means the student is accountable, not the tool. In professional settings, the writer and the publisher are accountable. ChatGPT does not knowingly plagiarize, but it can produce outputs that overlap with existing sources, so the human in the loop must verify originality and add proper citations before publication. Treat every AI draft as a junior writer's first attempt that needs editing, fact-checking, and a plagiarism scan.
Can educational institutions detect content generated by ChatGPT?
Yes, increasingly so. Major institutions have deployed Turnitin's AI detector, Copyleaks, Originality.AI, and GPTZero across their submission workflows. Detection accuracy varies by tool and by text length, with most production detectors reporting 90% or higher accuracy on passages longer than 300 words. Heavy editing of AI output reduces detection rates, but does not eliminate them. Many institutions now combine automated detection with stylometric analysis and authorship verification interviews for flagged submissions.
What are the academic consequences of using AI-generated content inappropriately?
Consequences scale with institutional policy and the severity of the violation. At the lower end, an academic integrity warning and a required revision. In the middle, course failure or a zero on the assignment. At the upper end, suspension, dismissal, or revocation of a degree if discovered after graduation. Several universities have published case-by-case sanctions that include permanent transcript notations. The trend is toward stricter enforcement as detection tools improve and institutional norms harden.
How accurate is the ChatGPT plagiarism checker?
There is no single "ChatGPT plagiarism checker" built by OpenAI. The accurate question is which third-party tool to use. Copyleaks reports 99.1% accuracy on AI detection across 30 languages. Turnitin claims 98% accuracy on AI generation detection. Originality.AI reports above 95% on AI content above 300 words. Plagiarism overlap detection, separate from AI detection, depends on the index size of the tool. Turnitin and Copyleaks have the deepest indexes, which makes their plagiarism reports the most reliable for academic and long-form content.
How should AI-generated content be treated to maintain authenticity?
Treat AI output as a draft, never as a final. Run it through a plagiarism checker, verify every factual claim against a primary source, rewrite to your editorial voice, add original first-party data or experience, and disclose AI assistance where applicable. The goal is not to hide that AI was used. It is to make sure that what is published meets the same originality, accuracy, and voice standards as work produced without AI help. Make chatbot sound human covers the same principle applied to conversational AI: the model is the engine, the human is the editor.
Further reading on ChatGPT and AI content:
Does ChatGPT Save Data? How to Control It in 2026
Vital ChatGPT Usage Statistics for 2026
Is ChatGPT Accurate? 2026 Stats, Hallucination Rates and Fixes
ChatGPT vs Notion AI: A Comparative Study for Productivity



